08/04/2016
Qué es el Web scraping? Introducción y herramientas
 Por Marq Martí @marqmarti
Por Marq Martí @marqmarti
El web scraping es una técnica que sirve para extraer información de páginas web de forma automatizada. Si traducimos del inglés su significado vendría a significar algo así como “escarbar una web”.
Aplicaciones y ejemplos: ¿Para qué sirve el web scraping?
Su uso está muy claro: podemos aprovechar el web scraping para conseguir cantidades industriales de información (Big data) sin teclear una sola palabra. A través de los algoritmos de búsqueda podemos rastrear centenares de webs para extraer sólo aquella información que necesitamos.
Para ello nos será muy útil dominar regex (regular expression) para delimitar las búsquedas o hacerlas más precisas y que el filtrado de la información sea mejor.
Algunos ejemplos para los cuales vamos a necesitar el web scraping:
- Para marketing de contenidos: podemos diseñar un robot que haga un ‘scrapeo’ de datos concretos de una web y los podamos utilizar para generar nuestro propio contenido. Ejemplo: scrapear los datos estadísticos la web oficial de una liga de fútbol para generar nuestra propia base de datos.
- Para ganar visibilidad en redes sociales: podemos utilizar los datos de un scrapeo para interactuar a través de un robot con usuarios en redes sociales. Ejemplo: crear un bot en instagram que seleccione los links de cada foto y luego programar un comentario en cada entrada.
- Para controlar la imagen y la visibilidad de nuestra marca en internet: a través de un scrapeo podemos automatizar la posición por la que varios artículos de nuestra web se posicionan en Google o, por ejemplo, controlar la presencia del nombre de nuestra marca en determinados foros. Ejemplo: rastrear la posición en Google de todas las entradas de nuestro blog.
¿Necesitas ayuda para scrapear información para tu negocio?
Ponte en contacto con nosotros y te daremos una solución a medida
¿Cómo funciona un web scraping?
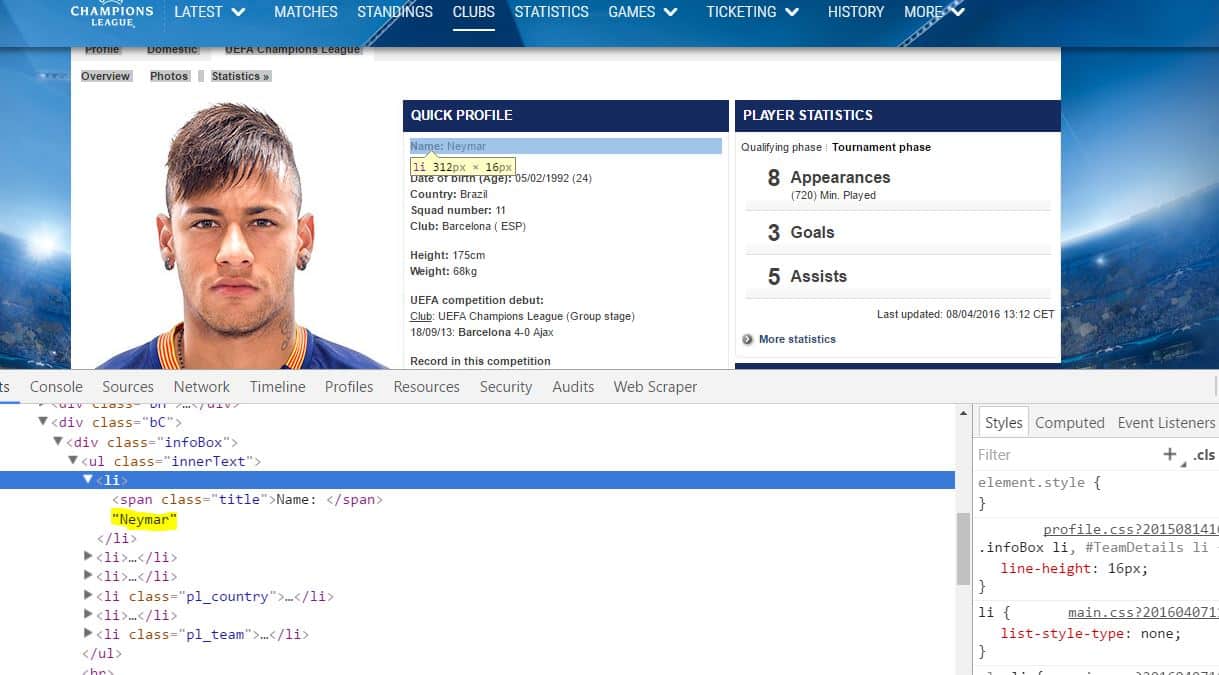
Pongamos un ejemplo básico de como funciona un web scraper. Imaginemos que nos interesa extraer el título de 400 páginas que tienen el mismo formato y se encuentran dentro de un mismo site. En cada una de las 400 páginas el título está dentro de un selector <h1> que a su vez está dentro de un <div> con la clase .header.
Lo que hará nuestro web scraper es detectar ese selector h1 que está dentro de la clase header (.header h1) y extraerá esa información en cada una de estas 400 páginas. Luego podremos obtener toda esa información a través de la exportación de los datos en formatos como un listado en .json o un fichero .csv.
Lo que de forma manual tardaríamos unas cuantas horas de absoluto aburrimiento y trabajo de mecánico nuestro web scraper lo puede realizar en apenas un par de minutos.
¿Qué conocimientos hay que tener para ser un buen web scraper?
El web scraping es una disciplina que debe combinar dos vertientes muy diferenciadas del conocimiento web, ambas esenciales para tener perfil versátil en la red. Por un lugar debemos dominar la visualización de datos a nivel conceptual y por el otro debemos disponer de los conocimientos técnicos necesarios para lograr extraer con exactitud los datos con herramientas especializadas.
Al fin y al cabo esto se resumirá en saber gestionar grandes cantidades de datos (big data). Debemos estar mínimamente familiarizados con la visualización de grandes cantidades de datos con tal de poder jerarquizar e interpretar los datos que extraigamos de una web. Y no solo para extraer los datos, también a la hora de plantear la estrategia de extracción debemos saber cuales van a ser los datos que vayamos a extraer con tal de poder darles un sentido informativo para el usuario.
Hay 3 puntos claves que debemos dominar para ser unos buenos web scrapers:
- 1. Conocimientos de maquetación web. Los web scraper funcionan seleccionando selectores html y para ello nos hará falta tener cuatro conocimientos básicos de arquitectura web.
- 2. Saber utilizar software para visualizar los datos como por ejemplo un procesador de hojas de cálculo de Google, conocido como Google Spreadsheets, o un editor de texto básico como Sublime.
- 3. Tener conocimientos de regex. Tener conocimientos mínimos de regex (también llamado regular expression) nos va a facilitar mucho el trabajo a la hora de trabajar con grandes cantidades de datos ya que puede ahorrarnos miles de horas de laborioso trabajo a la hora de corregir o depurar los datos antes de importarlos a plataforma deseada.
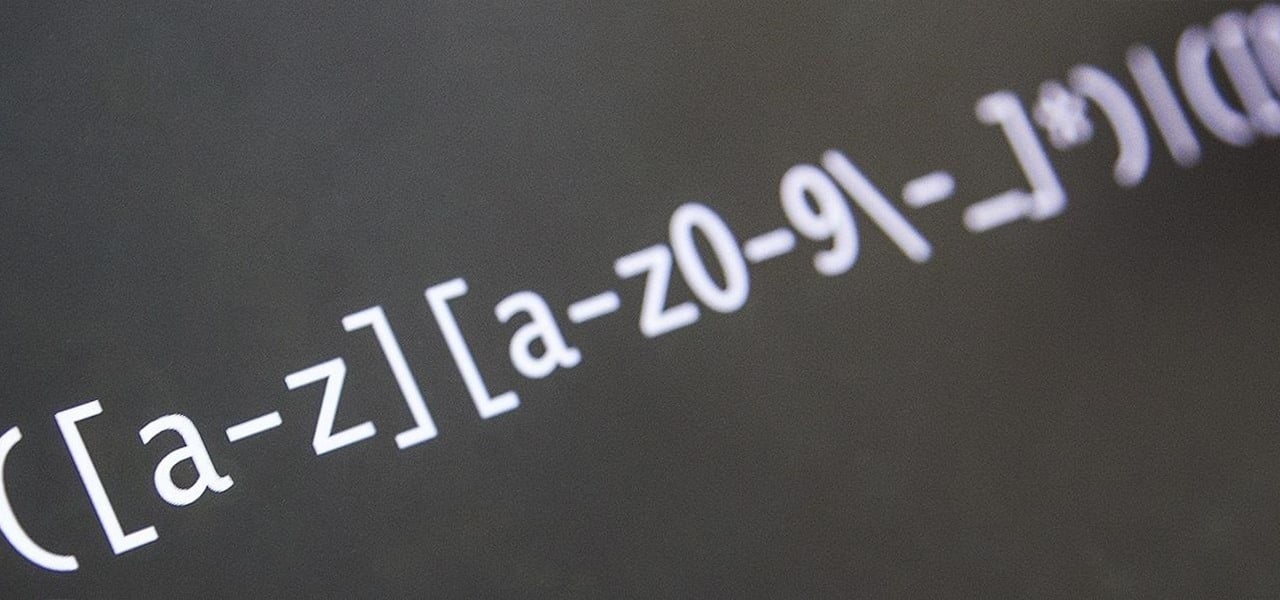
Expresión regular (regex) para delimitar una búsqueda
¿Y después del web scraping? Cómo utilizar los datos obtenidos
El web scraping consiste en obtener los datos pero evidentemente estos datos los tendremos que usar para alguna finalidad. Es aquí cuando entran en juego dos procesos claves una vez obtenidos los datos:
Jerarquización, ordenación y filtrado de los datos. Muchas veces cuando extraigamos cantidades industriales de datos, antes de importarlos a otra plataforma deberemos ‘trabajar’ estos datos con precisión con tal depurarlos para su importación.
Importación de los datos a otra plataforma. La importación de los datos se trata de otro proceso básico. Hay herramientas muy recomendables con las que podemos trabajar en plataformas como WordPress, como por ejemplo el plugin WP Ultimate CSV Importer del estudio de desarrollo Smack Coders (también disponen de una versión de pago, Ultimate CSV Importer Pro).
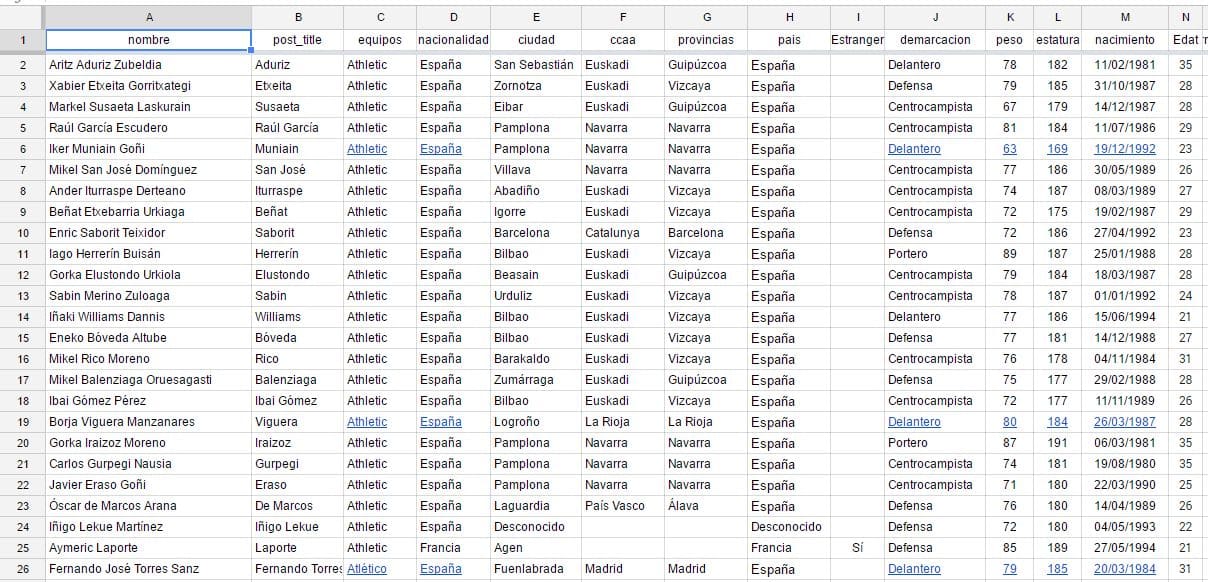
Hoja de Google Spreadsheets con datos extraídos con un web scrapper de las webs de laliga.es y uefa.com. Los datos estan listos para importarlos a una web que corre sobre el CMS WordPress a traves de la herramienta WP Ultimate CSV Importer
¿Qué herramientas hay para hacer web scraping?
Sin duda me decantaría por dos herramientas principales: webscraper.io y import.io. Otra tercera herramienta sería Scrapy.org. A continuación una breve descripción de cada una de las herramientas junto a una pequeña valoración de para quién van a ser útiles:
Webscraper.io
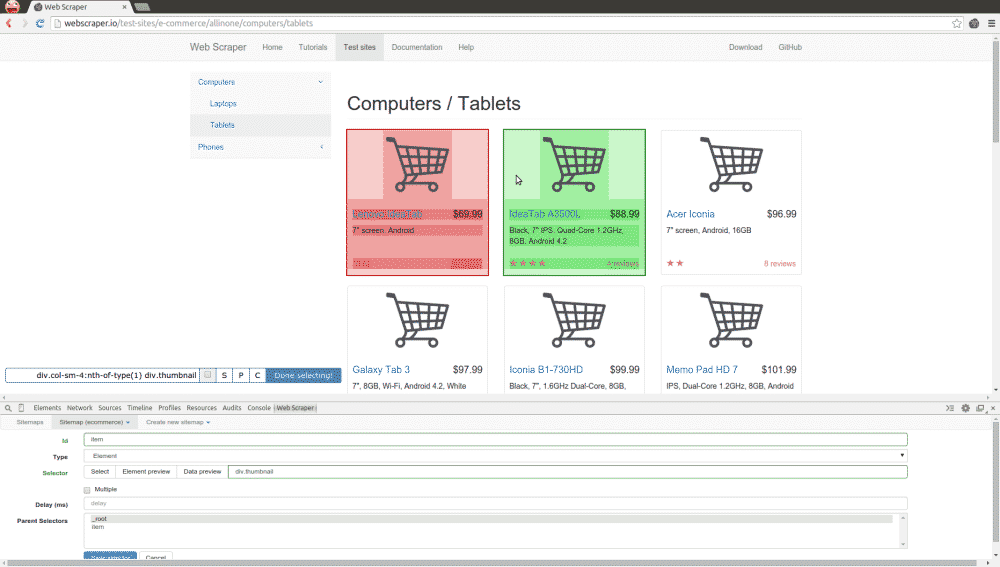
Es un plugin para el navegador de Google, Chrome. Desde mi punto de vista es la herramienta a la que más jugo se le puede sacar aunque para usarla hay que tener unos mínimos conocimientos de maquetación web para identificar correctamente los selectores html y, en algunos casos, también será útil disponer de algunas nociones de regex (regular expresion) para formular bien los comandos de ‘scrapeo’.
Es una herramienta recomendada para usuarios con un cierto conocimiento de programación y maquetación web.
Import.io
Se puede usar desde el panel de control de la web para scrapeos básicos aunque para operaciones más complejas es necesario descargarse el programa. El programa no es más que un navegador construido sobre la base del software libre de Chromium (el motor de Chrome) modificado especialmente para hacer web scraping. Es una herramienta fácil de usar y eso implica que no se deben tener conocimientos específicos de programación para empezar a experimentar con ella. Dispone de muchas opciones aunque la libertad para programar scraps de webscraping.io es mayor.
La pueden usar todo tipo de usuarios siempre que estan familiarizados con los conceptos básicos del mundo web y con herramientas de visualización de datos como Excel y Google Spreadsheets.
Scrapy.org

Es una herramienta que funciona con el lenguaje de programación Python. Para usarla, evidentemente, hay que disponer de conocimientos avanzados de programación en Python. Desde mi punto de vista es una herramienta bastante compleja de manejar y en absoluto abierta a todo el mundo. Otro handicap es que si se quieren usar los datos extraídos para trabajar con hojas de cálculo, el proceso se va a complicar de forma aritmética .
Es una herramienta 100% pensada para programadores con conocimientos avanzados de Python y para proyectos que no requieran mucho trabajo de visualización de datos a la hora de trabajar con los resultados del ‘scrapeo’ (es decir, sin usar herramientas más visuales como por ejemplo, las hojas de cálculo).
El web scraping como substitutivo de una API
Una API (Application Programming Interface, en castellano, interfície de programación de aplicaciones) es una herramienta que nos permite intercambiar datos entre varias webs. Pongamos por caso que tenemos un periódico deportivo y que en él tenemos una sección de estadísticas de los partidos de futbol.
Estos datos -en principio- no se rellenan de forma manual tras cada partido. Lo que suelen hacer las webs de los diarios deportivos es estar conectadas a empresas que disponen de centros de datos. Estas empresas se dedican a dar acceso a estos datos a través de APIs. Una API de este tipo normalmente será un servicio de pago.
Con un web scraper programado de forma periódica podemos acabar consiguiendo el mismo resultado para actualizar los datos de nuestra web. De hecho la herramienta import.io ya cuenta incluso con servicio que convierte el web scraper en una API. Eso sí, al contrario que la API, no se va a tratar de un proceso ‘en tiempo real’.
- Otros artículos relacionados
-
06/04/2015 (School of data)
Introducción a la extracción de datos de sitios web: scraping
-
22/11/2013 (Vida Digital)
Qué es el Web Scraping o Screen Scraping y por qué nos debe importar?
-
22/04/2013 (Hartley Brody)
I Don’t Need No Stinking API: Web Scraping For Fun and Profit


